Big Data & Scalable Computing Lab
- Algorithms/Sytems for Scalable Computing
- Data Science at Scale/Big Data Analytics
- Artificial Intelligence/Machine Learning
- High Performance Computing
- Graph Data Mining, Learning, and Visualization
Research Summary
Current Ph.D. Students:
- 1. Naw Safrin Sattar: Joined in 2017, working on big data and AI/ML methods. Expected graduation: Summer 2022.
- 2. Md Abdul Motaleb Faysal: Joined in 2017, working on big data and HPC. Expected graduation: Fall 2022.
- 3. Ted Holmberg: Joined in 2019, working on spatio-temporal data analytics. Expected graduation: Spring 2024.
- 4. Austin Schmidt: Joined in 2021, working on large-scale data analytics. Expected graduation: Spring 2025.
Sponsors
- National Science Foundation (NSF)
- US Dept. of Energy/Berkeley Lab/UC-Berkeley
- Louisiana Board of Regents
- UNO CoS
- UNO ORSP
Research Projects
-
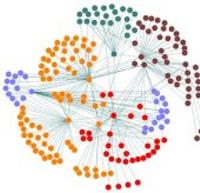
Complex systems are organized in clusters or communities, each having distinct role or function. In the corresponding network representation, each functional unit (community) appears as a tightly-knit set of nodes having a higher connection inside the set than outside. Finding communities may reveal the organization of complex systems and their function. We are currently working on designing parallel scalable algorithms for detecting communities in large-scale networks.
-
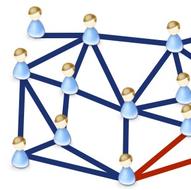 Counting triangles in a network is an important algorithmic problem arising in the study of complex networks. An efficient solution to the triangle counting problem can also lead to efficient solutions for many other graph-theoretic problems, e.g. computation of clustering coefficient, transitivity, and triangular connectivity. Further, triangle counting has important applications in graph analysis. We design efficient parallel algorithms for counting triangles.
Counting triangles in a network is an important algorithmic problem arising in the study of complex networks. An efficient solution to the triangle counting problem can also lead to efficient solutions for many other graph-theoretic problems, e.g. computation of clustering coefficient, transitivity, and triangular connectivity. Further, triangle counting has important applications in graph analysis. We design efficient parallel algorithms for counting triangles.
* Note that the above code is a research code and is intended for friendly use. The authors will try their best to address any questions/queries/issues. Users are advised to contact with the authors for any newer (or optimized) version of the code. However, for most general use cases, the provided code should suffice.
-
This project is an ongoing research collaboration with Lawrence Berkeley National Laboratory/University of California.
-

We are collaborating with Performance and Algorithms Group at Lawrence Berkeley National Lab on this project. Real complex systems are inherently time-varying and can be modeled as temporal graphs (networks). Examples include social, transportation, and many forms of biological networks. Standard graph metrics introduced so far in complex network theory are mainly suited for static graphs, i.e., graphs in which the links do not change over time. In this work, we aim at designing scalable parallel algorithms for mining large time-varying networks.
-

We are a multidisciplinary team consisting of faculty from Psychology/Neuroscience and Computer Science working together to extract insights from human brain data. Collaborators: Dr. Elliot Beaton and Dr. Vassil Roussev (UNO). Funded by UNO ORSP Interdisciplinary grant.
-

In this project, we identify several popular network visualization tools and provide a comparative analysis based on the features and operations these tools support. We demonstrate empirically how those tools scale to large networks. We also provide several case studies of visual analytics on large network data and assess performances of the tools.
-
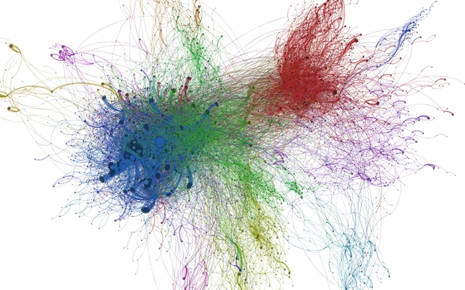
Characterizing real-world social and information networks based on graph-theoretic metrics or properties has been of growing interest. Among the most explored metrics are degree distribution, number of triangles and clustering coefficients. An important property related to triangles, of many networks, is high transitivity, which states that two nodes (vertices) having common neighbor(s) have an elevated probability of being neighbors to one another. We present a characterization of networks based on a quantification of common neighbors.
-
We are working to design scalable algorithmic and analytic techniques to study PPI networks. Our study of PPIs will be based on network-centric mining and analysis approaches. We will design specialized methods for extracting signed motifs, computing centrality, and finding functional units in PPI networks.